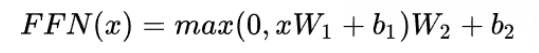Transformer
Transformer 是一个基于自注意力的序列到序列模型,与基于循环网络的序列到序列模型不同,其可以并行计算。
序列到序列模型
序列到序列模型输入和输出都是一个序列,输入和输出序列长度之间的关系有两种情况。第一种情况下,输入和输出的长度一样;第二种情况下,机器决定输出的长度。序列到序列模型有广泛的应用,比如常见的 语音识别、机器翻译与语音翻译,TTS,聊天机器人,问答任务,句法分析、多标签分类 等等。
Transformer 结构
一般的序列到序列模型会分成编码器和解码器。编码器负责处理输入的序列,再把处理好的结果丢给解码器,由解码器决定要输出的序列。
Transformer 编码器
Transformer 编码器使用的是自注意力,输入一排向量,输出一排长度相同的向量。编码器分成很多的块,每个块不是神经网络的一层,块的结构如图所示。

先跳过残差连接与层归一化的设计,在每个块里,输入一排向量后做自注意力,考虑整个序列的信息,再将输出丢到全连接网络里,输出另外一排向量,这一排向量就是块的输出。
这时候把残差连接和层归一化加进来,如图所示,最左边的向量 输入到自注意力层后得到向量 ,向量 加上向量 得到新的输出。这就是残差连接的过程。得到残差的结果后再做层归一化,得到层归一化的输出后,该输出才是全连接网络所的输入。输入到全连接网络,还有一个残差连接,把全连接网络的输入和它的输出加起来后得到新的输出,接着再把残差的结果再做一次层归一化得到的输出才是一个块的输出,这个块会重复 N 次。

Transformer 解码器
自回归解码器
比较常见的解码器为自回归解码器。解码器把编码器的输出先读进去,要想让编码器产生输出,首先要给它一个特殊 token < BOS >(Begin Of Sequence)。在机器学习里,每一个 token 都可以用一个独热向量表示。接下来解码器会吐出一个向量,该向量的长度和词表的长度是一样的,内容是各个字/词的概率,总和为 1,概率最高的结果就是输出。接下来再把这个结果当作解码器的新的输入,解码器看到 < BOS >、“结果 1”后会按照相同的过程输出结果 2,这个过程会反复地持续下去。

Transformer 的解码器内部结构如下图所示。类似于编码器,解码器也有多头注意力、残差连接和层归一化、前馈神经网络。解码器再做一个 softmax,使其输出变成一个概率。此外,由于解码器的输出是一个一个产生的,与原有的注意力不同,解码器使用了 mask self-attention,该 attention 可以通过一个掩码来阻止每个位置选择其后面的输入信息。
以下为一般的自注意力与掩蔽自注意力的对比 

要让解码器停止运作,需要另一个特殊的 token < EOS >,当输出 < EOS > 时,整个解码器产生序列的过程就结束了
非自回归解码器
假设产生中文的句子,非自回归不是一次产生一个字,它是一次把整个句子都产生出来。非自回归的解码器可能“吃”的是一整排的 < BOS > token,一次产生产生一排 token。因为输出的长度是未知的,所以当做非自回归解码器输入的 < BOS > 的数量也是未知的,因此有如下两个做法。
-
用分类器来解决这个问题。用分类器“吃”编码器的输入,输出是一个数字,该数字代表解码器应该要输出的长度。比如分类器输出 4,非自回归的解码器就会“吃”4 个 < BOS > 的词元,产生 4 个中文的字。
-
给编码器一堆 < BOS > 的词元。假设输出的句子的长度有上限,绝对不会超过 300 个字。给编码器 300 个,就会输出 300 个字,输出右边的的输出就当它没有输出。
非自回归的解码器有很多优点。第一个优点是平行化。自回归的解码器输出句子的时候是一个一个字产生的,假设要输出长度一百个字的句子,就需要做一百次的解码。但是非自回归的解码器不管句子的长度如何,都是一个步骤就产生出完整的句子,所以非自回归的解码器会跑得比自回归的解码器要快。另外一个优点是非自回归的解码器比较能够控制它输出的长度。
编码器-解码器注意力

关于编码器-解码器注意力的运作过程,如下图所示。编码器输入一排向量,输出一排向量 。接下来解码器会先 “吃” < BOS >,经过掩蔽自注意力得到一个向量,再把这个向量乘上一个矩阵,得到 。 也都产生 key 。把 和 相乘得到 ,再做 softmax 得到 ,通过 即可得加权和 ,最后交给全连接网络处理。
Transformer 的训练过程
以 “机器学习” 为例,把 < BOS > 丢给解码器的时候,其第一个输出与”机”越接近越好,而编码器的输出是一个概率的分布,即这个概率分布和“机”的独热向量越接近越好。因此我们会计算标准答案与分布之间的交叉熵,希望该交叉熵的值越小越好。每一次解码器在产生一个中文字的时候做了一次类似分类的问题

序列到序列模型训练常用技巧
复制机制(copymechanism)
以聊天机器人为例,用户对机器说:“你好,我是库洛洛”。机器应该回答:“库洛洛你好,很高兴认识你”。机器其实没有必要创造“库洛洛”这 个词汇,“库洛洛”对机器来说一定会是一个非常怪异的词汇,所以它可能很难在训练数据里面出现,可能一次也没有出现过,所以它不太可能正确地产生输出。但是假设机器在学的时候, 学到的并不是它要产生“库洛洛”,它学到的是看到输入的时候说“我是某某某”,就直接把“某某某”复制出来,说“某某某你好”。这种机器的训练会比较容易,显然比较有可能得到正确的结果,所以复制对于对话任务可能是一个需要的技术。机器只要复述这一段它听不懂的话,它不需要从头去创造这一段文字,它要学的是从用户的输入去复制一些词汇当做输出。最早有从输入复制东西的能力的模型叫做指针网络(pointer network),后来还有一个变形叫做复制网络(copy network)。
引导注意力
束搜索/贪心搜索/贪心解码
加入噪声
在做语音合成的时候,解码器加噪声,这是完全违背正常的机器学习的做法。在训练的时候会加噪声,让机器看过更多不同的可能性,这会让模型比较鲁棒,比较能够对抗它在测试 的时候没有看过的状况。但从正常角度讲,在测试的时候也加一些噪声,会把测试的状况弄得更困难,结果更差。但语音合成神奇的地方是,模型训练好以后。测试的时候要加入一些噪声, 合出来的声音才会好。用正常的解码的方法产生出来的声音听不太出来是人声,产生出比较好的声音是需要一些随机性的。对于语音合成或句子完成任务,解码器找出最好的结果不一定是人类觉得最好的结果,反而是奇怪的结果,加入一些随机性的结果反而会是比较好的。
使用强化学习训练
BLEU 现被广泛用于评价许 多应用输出序列的质量。解码器先产生一个完整的句子,再去跟正确的答案一整句做比较,拿两个句子之间做比较算出 BLEU 分数。但训练的时候,每一个词汇是分开考虑的,最小化的是交叉熵,最小化交叉熵不一定可以最大化 BLEU 分数。但在做验证的时候,并不是挑交叉熵最低的模型,而是挑 BLEU 分数最高的模型。一种可能的想法:训练的损失设置成 BLEU 分数乘一个负号,最小化损失等价于最大化 BLEU 分数。但 BLEU 分数很复杂,如果要计算两个句子之间的 BLEU 分数,损失无法做微分。我们之所以采用交叉熵,而且把每一个中文的字分开来算,就是因为这样才有办法处理。遇到优化无法解决的问题,可以用强化学习训练。具体来讲,遇到无法优化的损失函数,把损失函数当成强化学习的奖励,把解码器当成智能体,具体可参考论文“Sequence Level Training with Recurrent Neural Networks”
计划采样
测试的时候,解码器看到的是自己的输出,因此它会看到一些错误的东西。 但是在训练的时候,解码器看到的是完全正确的,这种不一致的现象叫做曝光偏差。
假设解码器在训练的时候永远只看过正确的东西,在测试的时候,只要有一个错,就会一步错步步错。因为解码器从来没有看过错的东西,它看到错的东西会非常的惊奇,接下来它产生的结果可能都会错掉。给解码器的输入加一些错误的东西,不要给解码器都是正确的答案,偶尔给它一些错的东西,它反而会学得更好,这一技巧称为计划采样 
Transformer的20个问题
参考transformer模型— 20道面试题自我检测_transformer面试题-CSDN博客
-
Transformer为何使用多头注意力机制?
多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。可以类比CNN中同时使用多个滤波器的作用
-
Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
使用Q/K/V不相同可以保证在不同空间进行投影,增强表达、泛化能力
-
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
Q和K的点乘是为了得到一个attention score矩阵,用来对V进行提纯,而且为了计算更快。作为整体计算attention时两个计算量相似,在效果上越大加法的效果越显著
-
为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
取决于softmax函数的特性,当softmax的输入过大/过小时,会存在梯度消失的情况。开根号是为了让点积的方差控制在1
-
在计算attention score的时候如何对padding做mask操作?
padding位置设为负无穷,在对attention score相加
-
为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
将原有的高维空间转化为多个低维空间并进行拼接,形成相同维度的输出,借此丰富特性信息
-
大概讲一下Transformer的Encoder模块?
Embedding+Position Embedding,multi-head attention,Add+LN,FN,Add+LN
-
为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
Xavier init初始化权重方式,使激活值分布均匀
-
简单介绍一下Transformer的位置编码?有什么意义和优缺点?
用来表示每一个token的位置信息。transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
-
你还了解哪些关于位置编码的技术,各自的优缺点是什么?
不知道,有待学习
-
简单讲一下Transformer中的残差结构以及意义。
ResNet的优点,即解决梯度消失
-
为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
LN:针对每个样本序列进行Norm,没有样本间的依赖,对一个序列的不同特征维度进行Norm
nlp领域认为句子长度不一致且各个batch的信息没什么关系,因此只考虑句子内信息的归一化
-
简答讲一下BatchNorm技术,以及它的优缺点。
-
优点:解决梯度饱和问题(sigmoid)加快收敛;降低学习难度加快收敛速度
-
缺点:batch_size较小时效果不好;在RNN中效果较差
-
-
简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
ReLU

-
Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
Cross Self-Attention,Decoder提供Q,Encoder提供K、V
-
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
encoder为masked self-attention,防止看到未来的信息
-
Transformer的并行化提现在哪个地方?
Encoder方面模块之间是串行的,但从每个模块内部来看注意力层和前馈神经层是可以并行的
-
Decoder端可以做并行化吗?
Decoder可以并行化训练,但推理是串行的
-
Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
看不懂,有待学习
-
解码端的残差结构有没有把后续未被看见的mask信息添加进来,造成信息的泄露。
未造成信息泄露,在multi-head attention里对未来时刻的输入已经被计算为0或无贡献的值